Ségrégation résidentielle due au revenu imposable dans la zone métropolitaine d’Athènes
Pantazis Panayotis|Psycharis Yannis
Structure Sociale
2016 | Jan
Approches conceptuelles de la ségrégation par le revenu
Le revenu est un facteur déterminant dans le choix du domicile, tandis que le coût du logement est étroitement lié au coût des habitations voisines. Les agents immobiliers, les évaluateurs et les acheteurs utilisent les prix récents des biens-fonds comparables sur les marchés immobiliers locaux pour évaluer le niveau des prix. Parallèlement, vu que les prêts hypothécaires sont liés au revenu, les choix des habitants sont limités par leurs revenus. En général, ces mécanismes posent (ne serait-ce que grosso modo) des contraintes de revenu aux personnes qui choisissent de vivre dans un certain quartier, ce qui aboutit à une hiérarchisation des lieux de résidence en fonction du revenu. Cette ségrégation liée au revenu – c’est-à-dire la répartition inégale des individus et des foyers dans différentes unités spatiales sur la base du revenu- est particulièrement sensible dans la plupart des villes et se caractérise essentiellement par trois paramètres :
- Tout d’abord la classification des zones résidentielles en fonction du revenu peut conduire à ce qu’on appelle la ségrégation de la prospérité ou la ségrégation de la pauvreté − l’expression « ségrégation de la prospérité » indique la répartition inégale des ménages avec un revenu haut ou moins élevé au niveau local, la « ségrégation de la pauvreté » étant déterminée par la répartition inégale des familles avec un revenu faible ou moins faible selon la fragmentation spatiale.
- Un deuxième aspect important de la ségrégation liée au revenu est sa connexion avec des entités géographiques présentant un autre type de ségrégation sociale (p.ex. raciale). Les préférences des habitants pour leurs voisins contribuent à créer des hiérarchies entre les zones résidentielles, qui ne s’identifient pas, mais sont complémentaires à celles résultant de l’inégalité des revenus.
- Un troisième aspect de la ségrégation liée au revenu est l’échelle géographique. La hiérarchisation des habitants sur la base du revenu peut s’exprimer surtout par des formes de hiérarchisation des zones résidentielles à grande échelle (ce qui serait le cas si toutes les familles à haut revenu vivaient en banlieue et toutes les familles à faible revenu au centre-ville) ou à petite échelle (comme dans le cas où des habitants à haut et à faible revenus se répartiraient dans une métropole selon une carte ressemblant à un échiquier, des quartiers riches homogènes côtoyant des quartiers pauvres homogènes).
La ségrégation est un processus qui présente un degré élevé d’hétérogénéité. En ce qui concerne l’analyse des effets spatiaux entre groupes socioprofessionnels, on distingue deux composantes conceptuelles de ségrégation résidentielle :
- La première composante est l’exposition spatiale (spatial exposure) ou, en d’autres termes, l’isolation spatiale (spatial isolation). L’exposition spatiale évalue dans quelle mesure les gens qui appartiennent à un groupe défini ont tendance à rester isolés de membres d’autres groupes (ou au contraire à s’y mélanger).
- La deuxième composante est l’uniformité spatiale (spatial evenness) ou regroupement spatial (spatial clustering). Il s’agit de la manière dont les membres d’un groupe se répartissent, en évaluant dans quelle mesure leur répartition dans l’espace est uniforme ou, d’une autre manière, dans quelle mesure les membres de ce groupe se situent plus ou moins près l’un de l’autre.
Données et zone d’étude
Les données quantitatives utilisées pour le traitement statistique proviennent du Secrétariat général aux Systèmes informatiques (GGPS) du ministère des Finances ; elles concernent les déclarations d’impôt des personnes physiques par code d’acheminement postal. Ces données contiennent entre autres : le nombre des déclarations, le montant du revenu déclaré (à la valeur courante), par tranches de revenus prédéterminées et par catégories professionnelles larges. La période pour laquelle ces données sont disponibles couvre les années fiscales 2003 à 2013.
Tableau 1:
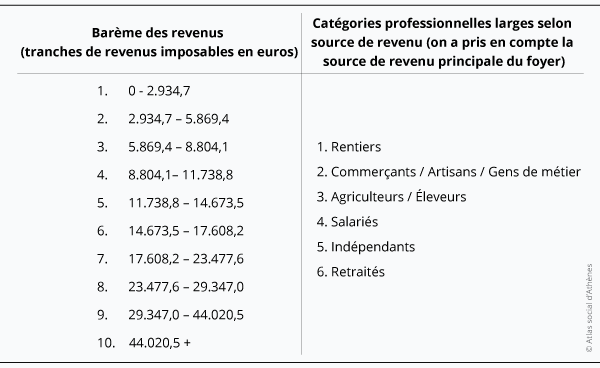
Le revenu déclaré pris en compte peut dévier de la formulation exacte de la prospérité, dans la mesure où il ne reflète pas la taille (inconnue) de l’économie parallèle et de la fraude fiscale.
- Quand bien même on tenterait une approche pour évaluer la taille de l’économie parallèle au niveau national, il n’est pas possible d’établir un constat du degré d’hétérogénéité spatiale de cette économie parallèle au niveau local.
- D’un point de vue diachronique, comme on le constate par le relevé des données ci-après, on observe une fluctuation importante du revenu déclaré –spécialement dans certaines catégories professionnelles– surtout en raison des changements de lois fiscales (p.ex. changement des critères de revenus présumés, obligation de déposer une déclaration, même en cas de revenu nul, au cas où l’on possède une propriété foncière), ce qui bouleverse la courbe de distribution du revenu imposable et modifie le calcul du revenu moyen.
- L’utilisation de barèmes de revenus stables avec des valeurs courantes peut créer des problèmes quand il s’agit de comparer à long terme l’inégalité de revenu, spécialement pour les périodes de changements économiques intenses.
La zone couverte par notre étude couvre l’ensemble de la Région Attique et comprend 508 entrées correspondant au code postal, dont 289 sont définies spatialement. Les autres entrées correspondent à des boîtes postales ou à des bureaux de poste ; il n’est donc pas possible de les rattacher à un lieu géographique.
Observation générale
La Région Attique représente plus de 42% du revenu déclaré des personnes physiques du pays, même si l’on observe une tendance régulière à la baisse au cours des années 2003-2013 (figure 1). Le revenu déclaré moyen (ratio du revenu déclaré sur le nombre de déclarations) reste stable, au dessus de 115% de la moyenne nationale pour toute la période étudiée. L’évolution du revenu déclaré moyen tant au niveau national qu’au niveau de l’Attique, peut être séparée grosso modo en trois périodes (figures 2.1 et 2.2) : a) Pour la période 2003-2008, on observe une tendance à la hausse forte et stable, qui culmine en 2008 (18 900 euros) et qui est liée au climat économique général de la période. b) Pour la période 2008-2010 on observe une relative stabilité (à des niveaux élevés), qui ne semble pas concorder avec les conditions socio-économiques plus larges, mais est peut-être due au changement de régime fiscal de 2009, les tendances à la compression du revenu disponible étant compensées par l’élargissement de l’assiette fiscale. c) De 2011 à 2013 toutefois on perçoit l’impact de la crise économique et financière sur le produit fiscal, avec une baisse rapide jusqu’en 2013 ; le niveau du revenu déclaré moyen (en valeurs constantes) tombe en dessous du niveau de 2003. Il convient de nous arrêter ici sur l’évolution du revenu moyen, qui révèle des changements de distribution importants : jusqu’en 2005 on voit que ce sont des valeurs extrêmes, hautes et basses, qui affectent la valeur du revenu déclaré moyen (figures 2.1 et 2.2).
Figure 1 : Part de la Région Attique au total des déclarations d’impôt et du revenu déclaré pour l’ensemble du pays (2003-2013)
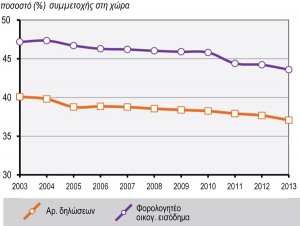
Source : GGPS 2004-2014
Figure 2.1 : Évolution du revenu déclaré moyen en valeur constantes 2005, pour la Région Attique et pour l’ensemble du pays (2003-2013)
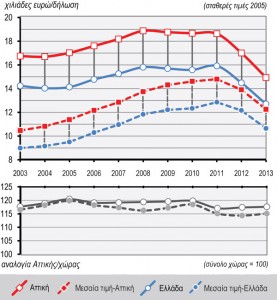
Source : GGPS 2004-2014
Figure 2.2 : Distribution du revenu déclaré moyen en valeurs constantes 2005 pour la Région Attique (2003-2013)
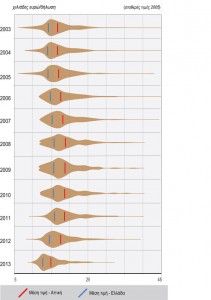
Source : GGPS 2004-2014
En ce qui concerne la distribution des déclarations d’impôt et la valeur du revenu déclaré par tranches pour la période 2003-2013 (figure 3), on observe une augmentation progressive de la contribution des tranches élevées aux dépens des tranches moyennes-faibles jusqu’en 2010. La tendance s’inverse en 2011, avec la compression de la tranche inférieure et l’élargissement des tranches faibles-moyennes, avec retour à des niveaux de ratio des années précédentes. Diachroniquement, l’inégalité de revenu, comme formulée par l’indice de Gini (figure 4.1), est liée à l’augmentation du revenu déclaré moyen jusqu’en 2010, à la chute rapide aux niveaux de 2003 et à la stabilisation des deux dernières années (2012-2013). De même, la polarisation relative (càd le ratio des deux tranches de revenus les plus élevées sur les deux tranches les plus basses) fait ressortir la différence dans le rythme de changement des tranches de revenu supérieures et inférieures tant au cours de la période d’augmentation que durant la période de récession (figure 4.2).
Figure 3 : Distribution des déclarations d’impôt et du revenu déclaré en 10 tranches pour la Région Attique et l’ensemble du pays (2003-2013)
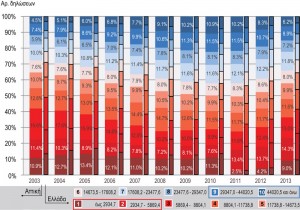
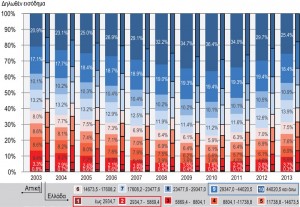
Source : GGPS 2004-2014
Figure 4.1 : Indice de Gini (inégalité de revenu) du revenu déclaré pour la Région Attique (2003-2013)
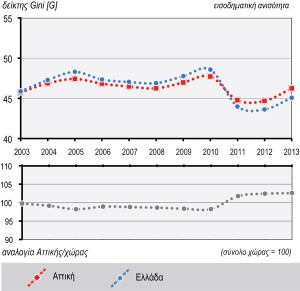
Figure 4.2 : Indice de dispersion de l’inégalité de revenu (ratio revenus élevés/revenus faibles) du revenu déclaré pour la Région Attique (2003-2013)

En ce qui concerne la distribution en catégories professionnelles plus larges, les remarques principales se résument dans les points suivants (figure 5.1) : Les catégories Salariés et Retraités constituent la source principale du produit fiscal des personnes physiques. L’élargissement de l’assiette fiscale au cours des trois dernières années fait apparaître une légère augmentation de la contribution de la catégorie Rentiers dans les déclarations, sans toutefois que leur contribution soit proportionnelle au revenu déclaré comme on pouvait s’y attendre. Au contraire, le poids spécifique de la catégorie Retraités augmente progressivement à partir de 2003 (participation aux déclarations et au revenu), ce qui indique également les problèmes structurels de l’emploi en Grèce comme en Attique. Les catégories Commerçants-Artisans / Gens de métier et Indépendants, qui constituent théoriquement la partie supérieure de la stratification socio-économique, conservent de façon quasi stable leur place sur la base du revenu déclaré, tout en ne fournissant qu’une part de plus en plus petite de l’ensemble des recettes fiscales des personnes physiques. Toutes les catégories professionnelles de la Région Attique se situent clairement au dessus de la moyenne nationale en ce qui concerne le revenu déclaré. Avec le temps, la diminution des revenus « se décale » après 2010, où l’on note les coupes les plus importantes sur les salaires et les retraites, bien que les catégories Commerçants-Artisans / Gens de métier et Indépendants semblent être plus frappées par la crise économique (figure 5.2).
Figure 5.1 : Distribution des déclarations d’impôt et du revenu déclaré par catégories professionnelles larges, pour la Région Attique et l’ensemble du pays (2003-2013)
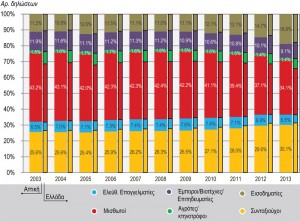
Source: GGPS 2004-2014
Figure 5.2 : Revenu déclaré moyen des catégories professionnelles larges en valeurs constantes 2005, pour la Région Attique et l’ensemble du pays (2003-2013)
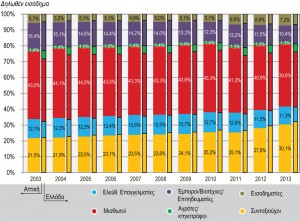
Source: GGPS 2004-2014
Inégalité spatiale
La cartographie du revenu déclaré dans l’espace métropolitain d’Athènes pour l’année 2013 montre des formes facilement discernables de concentrations de valeurs élevées et basses (carte 1.1). À titre de comparaison, on trouvera ici des cartes réduites pour les années 2003, 2008, 2010. L’axe de ségrégation résidentielle est-ouest facilement reconnaissable –grâce à des études précédentes (Μαλούτας 2001, Καλογήρου 2011)–, et l’axe centre-périphérie avec quelques différenciations locales nord-sud, en particulier dans le secteur est de la Région Attique, apparaissent très clairement. Plus précisément, c’est dans le secteur nord-est de l’ensemble urbain (Erythraia, Ekali, Néa Pentéli, Vrilissia), au centre de la municipalité d’Athènes dans les quartiers autour du Lycabette (Kolonaki, place Mavili, Evangelismos), dans le secteur sud (Voula, Vouliagmeni) ainsi que dans une enclave qui comprend Psychiko et quelques quartiers de la municipalité de Philothéi, que l’on observe les valeurs les plus élevées de revenu déclaré. La zone ouest de la municipalité d’Athènes, centrée sur le Métaxourgio, certaines zones des municipalités d’Agiou Ioanni Renti et de Tavros, quelques secteurs de la zone nord-ouest (Aspropyrgos, Phyli, Acharnes et Kamatéro) constituent l’autre face de la pièce, avec les valeurs les plus petites. Par ailleurs, la « mobilité » des zones étudiées pour la hiérarchisation liée au revenu est limitée pour l’extrémité supérieure de la distribution, tandis que les zones à revenu faible-moyen ont les probabilités les plus élevées de « passer » soit plus haut soit plus bas (tableau 2.1).
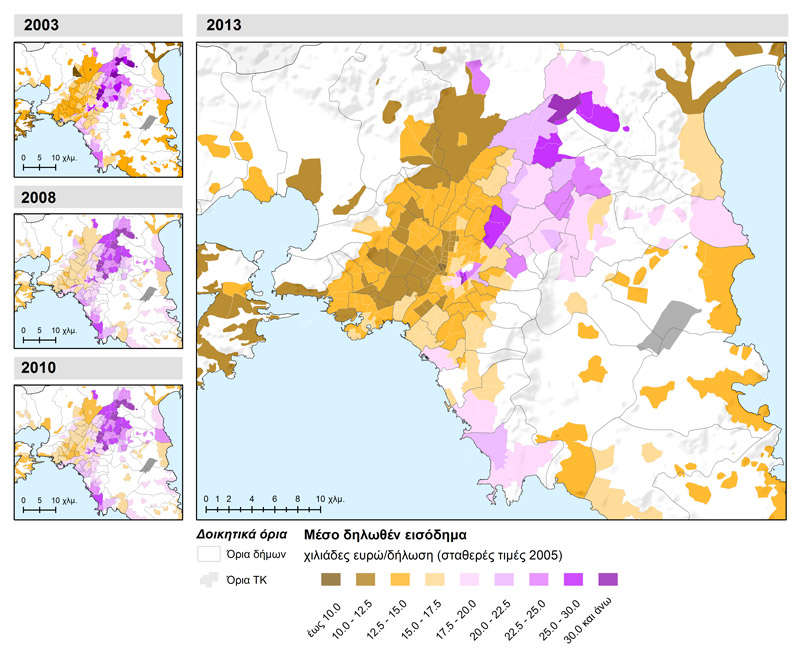
Carte 1.1 : Revenu déclaré moyen par code postal dans la zone métropolitaine d’Athènes pour les années fiscales 2003, 2008, 2010 et 2013
Tableau 2.1 : Tableau des probabilités de passage de la distribution initiale à la distribution finale en déciles pour les valeurs du revenu déclaré moyen, dans les unités d’analyse spatiale de la zone métropolitaine d’Athènes pour la période 2003-2013
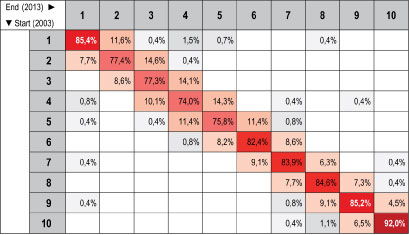
| Pour étudier la « mobilité » d’un système, on utilise la méthode statistique de la chaîne de Markov : on étudie la probabilité de changement de la distribution des valeurs à partir d’un état donné (initial) jusqu’à un état final suivant un processus de transition à pas discrets. La probabilité (hypothétique) de distribution du système à l’étape suivante (et fondamentalement, à tous les autres pas futurs) dépend seulement de l’état présent du système et non cumulativement de l’état du système aux étapes précédentes.
En l’occurrence, on entend par « système » la distribution géographique du revenu déclaré moyen, par « état » la distribution du revenu déclaré par tranches de revenus et par « étape, pas » les relevés annuels des valeurs de la variable examinée. Pour les besoins de la présente présentation, nous avons utilisé une méthode statistique qui tient compte également des valeurs voisines de chaque unité spatiale (Rey, 2001). On obtient ainsi un tableau à deux entrées qui contient les probabilités d’une valeur de « passer » d’une tranche de revenu à une autre depuis l’année initiale à la dernière année de la période étudiée. Les cases qui forment la diagonale de la matrice de transition donnent les probabilités pour une région de se maintenir dans la même tranche de revenu entre le début et la fin de la période. Les valeurs élevées indiquent la stabilité dans l’évolution spatiotemporelle du phénomène de distribution du revenu déclaré. Les valeurs qui se trouvent dans la partie supérieure du tableau (au dessus de la diagonale) indiquent un déplacement vers un niveau de revenu relativement inférieur ; inversement, les valeurs dans la partie inférieure du tableau, indiquent un déplacement vers un niveau de revenu relativement plus élevé. |
La distribution spatiale inégale du revenu dans l’espace athénien se vérifie statistiquement par l’analyse de l’autocorrélation spatiale –c’est-à-dire en contrôlant le voisinage des régions ayant des valeurs similaires. Les valeurs élevées de l’indice total d’autocorrélation I de Moran (supérieures à 0,5 sur une échelle de 0 à 1) indiquent des tendances importantes à la concentration spatiale. Du point de vue diachronique, les modèles géographiques de ségrégation par le revenu demeurent quasi inchangés ; il faut cependant souligner la polarisation progressive de l’espace urbain avec des groupes élargis de valeurs élevées dans le secteur nord-est et au centre de l’agglomération et des concentrations certes moins compactes mais tout aussi larges de valeurs basses dans le secteur occidental de la zone centrale et dans le secteur ouest de la Région Attique. Des enclaves de valeurs basses s’observent dans le secteur nord (Acharnes, Marathon) même si au fil du temps, compte tenu de la convergence vers le bas des zones à revenu faible et faible-moyen, elles sont de moins en moins nombreuses (carte 1.2). Globalement on observe une « inertie » importante dans le changement du modèle spatial de la ségrégation par le revenu (tableau 2.2).
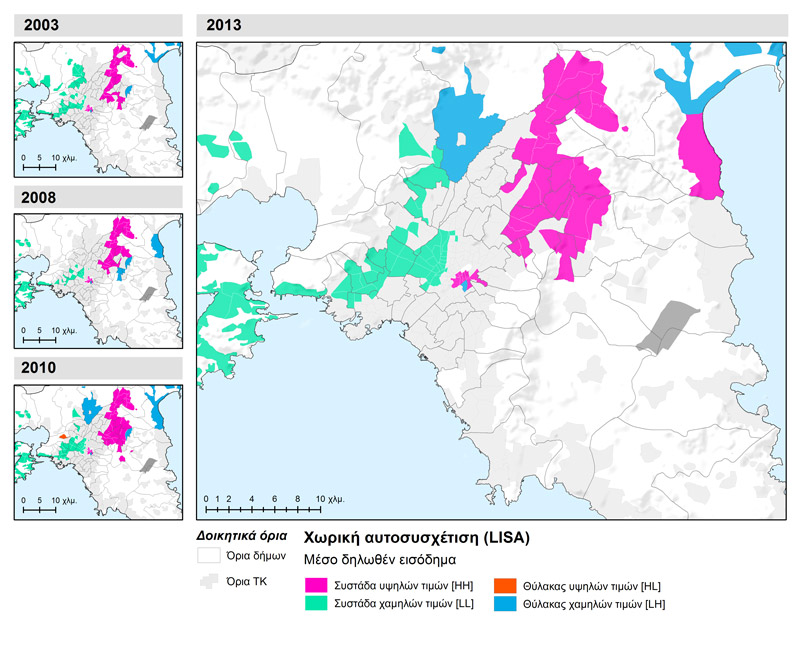
Carte 1.2: Clusters et enclaves de valeurs hautes et basses du revenu déclaré moyen dans les unités spatiales d’analyse de la zone métropolitaine d’Athènes (2003, 2008, 2010 et 2013)
| L’autocorrélation spatiale renvoie au degré de corrélation entre paires de valeurs d’une variable et à leur distance (géographique) entre elles. La logique du test s’appuie sur la comparaison de la valeur –de la variable à vérifier– de chaque unité spatiale avec la distribution des valeurs des unités spatiales voisines.
Une autocorrélation positive, ce qui est le cas le plus fréquent, indique que des valeurs égales (similaires) de la variable à vérifier tendent à se regrouper spatialement. La concentration des valeurs qui se trouvent au sommet de la distribution {groupe de valeurs élevées [HH-(High–High)]}, de même que la concentration des valeurs dans la partie inférieure de la distribution {groupe de valeurs basses [LL-(Low–Low)]} sont très fortes. Une autocorrélation négative indique la proximité d’unités spatiales avec des valeurs (in)égales, ce qui signifie la présence d’unités spatiales isolées soit avec des valeurs hautes dans des zones où prédominent des valeurs basses {enclave de valeurs hautes [HL-(High–Low)}, soit inversement, d’unités spatiales avec des valeurs relativement basses entourées de zones à valeurs hautes {enclave de valeurs basses [LH-(Low–High)}. Enfin, l’absence d’autocorrélation spatiale signifie qu’il n’y a pas de relation évidente entre proximité spatiale et distribution des valeurs de la variable. |
Tableau 2.2 : Probabilités de passer de la distribution initiale à la distribution finale pour les concentrations spatiales du revenu déclaré moyen, dans les unités spatiales d’analyse de la zone métropolitaine d’Athènes entre 2003 et 2013
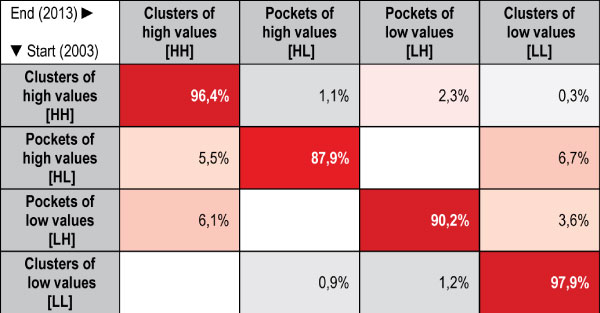
| La logique interprétative du tableau repose sur le commentaire au tableau 2.1. L’application de la méthode des chaînes de Markov se concentre sur la recherche de la dynamique de la distribution du revenu déclaré sur la base de la concentration ou de la dispersion des valeurs dans l’espace.
Les cases qui forment la diagonale de la matrice de transition donnent les probabilités pour une zone de conserver le même rapport avec ses voisines du début à la fin de la période. Des valeurs élevées indiquent la probabilité pour une zone de se maintenir à la même place du modèle spatial défini par l’analyse de l’autocorrélation spatiale (carte 1.2). Les valeurs dans les autres cases du tableau représentent la probabilité de « passage » d’une unité spatiale dans une distribution ayant une « relation » différente avec les unités voisines. |
L’inégalité de revenu s’exprime au niveau local par l’indice de Gini pour chaque unité spatiale (carte 2.1). La dispersion des valeurs de l’indice dans l’espace suit dans une large mesure la forme de distribution géographique du revenu déclaré et confirme la grande corrélation entre inégalité (concentration de revenu dans de petits groupes de population) et niveau de revenu, en particulier dans les zones de revenus moyens et supérieurs. L’absence de déclarations concernant les tranches de revenu supérieures dans des zones faiblement peuplées ou agricoles contribue à faire apparaître de faibles niveaux d’inégalité dans ces zones. On aboutit à la même conclusion avec les résultats de l’analyse de l’indice de concentration relative (carte 2.2), où la couleur foncée indique une concentration de revenus dans les tranches de revenu supérieures et une présence de ces tranches plusieurs fois plus grande que celle des bas revenus.
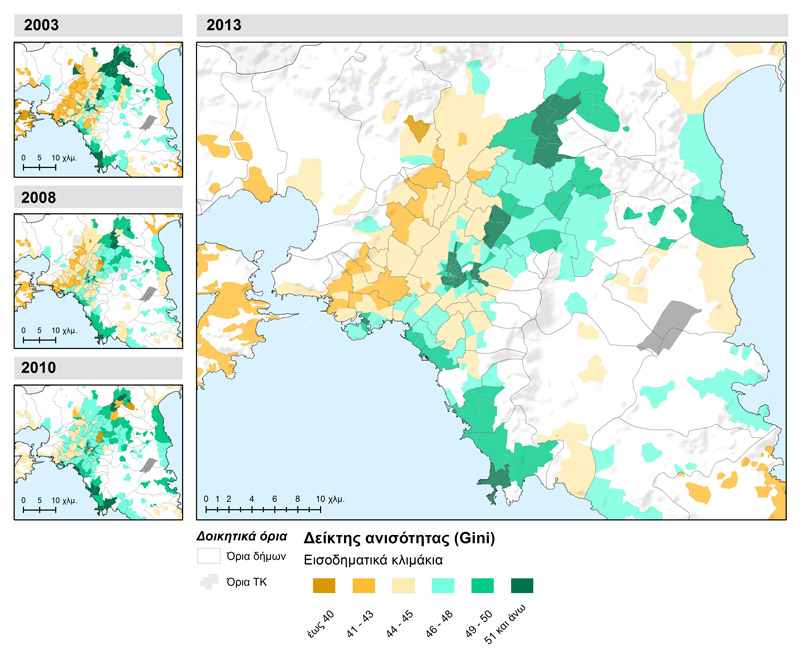
Carte 2.1 : Indice local de Gini (distribution inégale de revenus) du revenu déclaré moyen des unités spatiales d’analyse (codes d’acheminement postal) dans la zone métropolitaine d’Athènes (2003, 2008, 2010 et 2013)
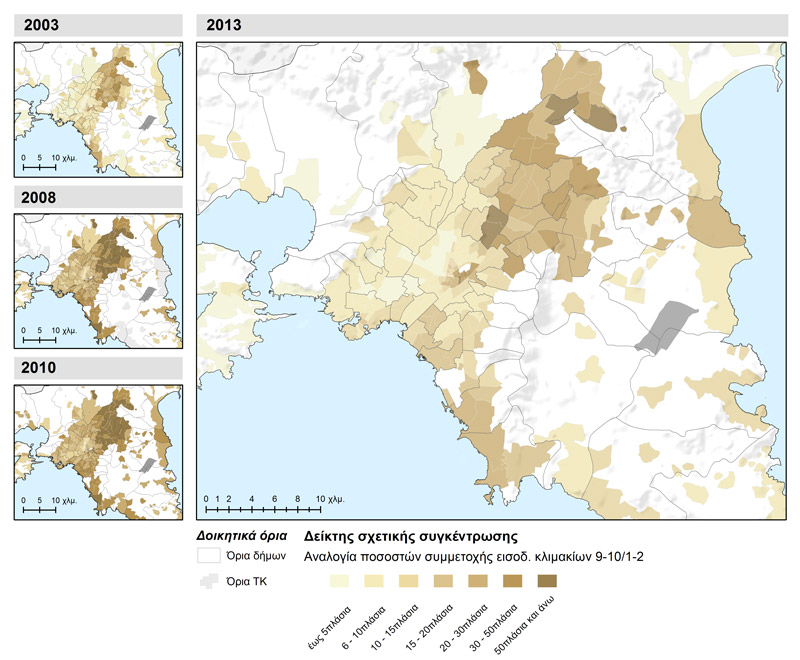
Carte 2.2 : Indice de concentration relative (ratio du revenu des tranches extrêmes du barème des revenus) des unités d’analyse spatiales dans la zone métropolitaine d’Athènes (2003, 2008, 2010 et 2013)
Pour représenter les modèles de concentration des catégories professionnelles, nous avons appliqué une méthode alternative pour définir dans quelle mesure une catégorie est surreprésentée dans une unité spatiale par rapport à l’ensemble de la zone étudiée, ainsi que pour les grandes zone de voisinage (carte 3.1). La catégorie Retraités présente des taux élevés de contribution dans le secteur central de l’agglomération athénienne ainsi qu’à Salamine et à Lavrio, ce qui est sans aucun doute lié à la structure démographique de la population dans ces zones de la Région Attique. Les Salariés –la catégorie la plus nombreuse– prédominent dans la plupart des unités spatiales. Le modèle qui s’en dégage forme un anneau large entourant la municipalité d’Athènes, particulièrement fort dans le secteur nord-nord-ouest de l’agglomération du Grand-Athènes. La catégorie Indépendants au contraire forme un groupe compact avec une délimitation géographique claire dans des zones-anneaux de concentration relative, au centre et dans le secteur nord-est de l’agglomération. Quant aux Rentiers, on distingue nettement la formation de groupes de faible ampleur avec une composition sociale hétérogène, avec un taux de contribution élevé aussi bien dans le secteur nord que dans le secteur sud, mais aussi dans les « beaux » quartiers du centre. La catégorie Agriculteurs se localise, comme on pouvait s’y attendre, dans des zones à faible densité de construction. C’est la zone du centre qui présente la plus grande diversification en ce qui concerne la composition professionnelle (carte 3.2), tandis que les zones avec la plus grande homogénéité (absence de plusieurs catégories) sont liées au montant du revenu déclaré.
Carte 3.1 : Catégories professionnelles de la source principale de revenu des foyers par zones de voisinage successives dans les unités d’analyse spatiales de la zone métropolitaine d’Athènes (2013)
| On considère comme zones avec surreprésentation de certaines catégories de la population les zones où le taux dépasse de deux écarts-types la moyenne de la zone analysée (Deurloo & Musterd 2001). L’écart-type est calculé sur la base de la distribution binomiale étant donné que sont impliqués deux facteurs : les déclarations d’impôt d’une catégorie professionnelle et le reste des déclarations. La formule est :
ΤΑ= √(p*q/n) Où : p, pourcentage du groupe examiné dans la zone étudiée, q = 1 – p, pourcentage des autres catégories dans la zone étudiée, n, population moyenne de la catégorie examinée pour chaque unité spatiale. On examinera également la probabilité de concentration des catégories de population dans des zones résultant de rayons successifs du test de proximité. On recalcule les pourcentages des catégories de population dans les zones et on reporte sur la carte les cas qui dépassent le seuil de deux écarts-types par rapport à la moyenne de la catégorie de la zone étudiée. Cette méthode fait apparaître différents modèles de distribution définis par la composition des unités spatiales voisines en fonction du rayon du test de proximité. La surreprésentation avec différents rayons indique le degré d’homogénéité de la distribution des valeurs de la catégorie examinée. L’interprétation de la carte 3.1 peut être formulée comme suit :
|
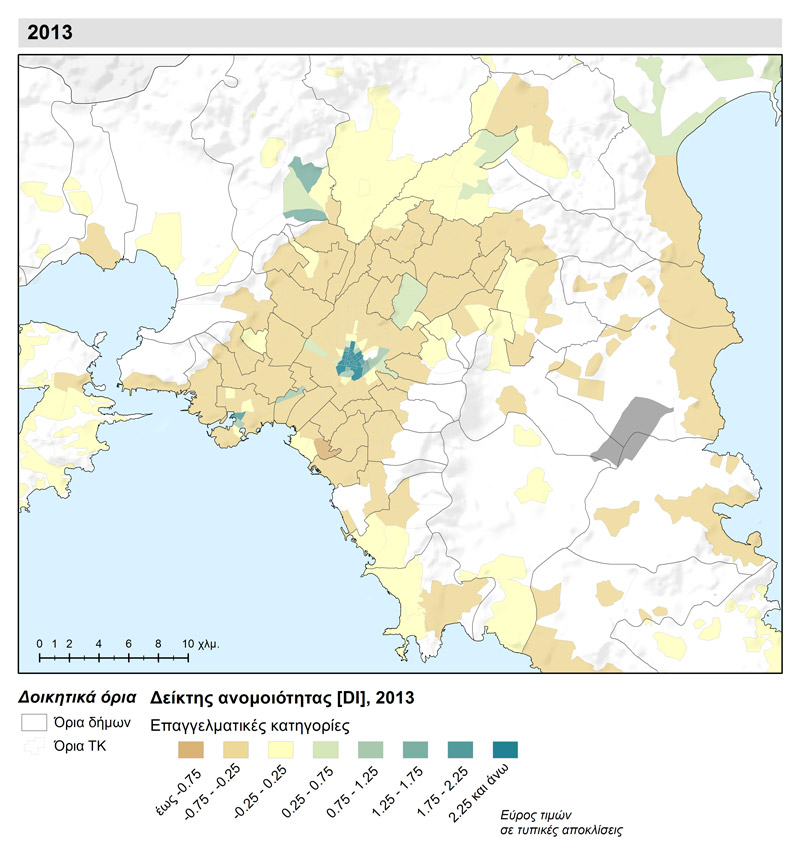
Carte 3.2 : Catégories professionnelles de la source principale de revenu des foyers par zones de voisinage successives dans les unités d’analyse spatiales de la zone métropolitaine d’Athènes (2013)
La dynamique spatiale, pour ce qui est des catégories professionnelles larges, telle que définie par l’évolution des indices de ségrégation complexes (multigroupes) au cours du temps (Reardon et al. 2008), présente une tendance claire à la diminution de tous les indices de ségrégation (figure 6.1). Cela signifie que l’on a affaire spatialement à des processus de redistribution et de dispersion lentes de la population des catégories professionnelles dans les unités spatiales examinées qui s’accompagnent d’une atténuation des polarisations spatiales et d’une homogénéisation au niveau local, en particulier pour les catégories à gros effectif. Plus précisément, l’inégalité spatiale (indice de Gini) se trouve à des niveaux relativement bas, étant donné que, au cours du temps, seuls 12 à 15% de la population devront être redistribués pour atteindre une distribution égale complète. De la même façon, l’indice de dissimilarité (D) qui exprime la polarisation spatiale avec, logiquement, une concentration des groupes à faible effectif, présente une tendance à la baisse au cours des dernières années, ce qui indique de profonds changements dans la composition des unités spatiales avec « déplacement » de population des zones non homogènes vers des zones plus homogènes. En ce qui concerne les indices correspondants par catégories professionnelles (figure 6.2), on constate des niveaux de distribution inégale (indice de Gini) relativement stables et élevés pour les catégories Agriculteurs / Éleveurs et Indépendants, tandis que pour les autres catégories, le niveau des valeurs de l’indice est nettement plus bas avec une tendance à diminuer encore. L’isolement relatif des catégories partielles semble diminuer au cours du temps, la catégorie des Salariés jouant le premier rôle dans cette tendance, ce qui indique dans une certaine mesure, le « départ » des autres catégories à faible effectif de certaines zones où elles étaient surreprésentées.
Figure 6.1 : Indices de ségrégation multivariée selon la catégorie professionnelle de la source principale de revenu dans la zone métropolitaine d’Athènes, entre 2003 et 2013
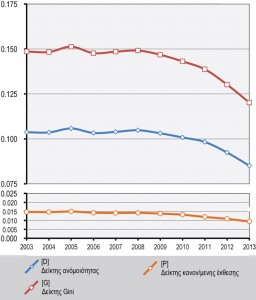
Figure 6.2 : Indices de ségrégation des catégories professionnelles de la source principale de revenu dans la zone métropolitaine d’Athènes, entre 2003 et 2013
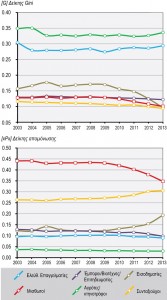
| Mesures de la ségrégation des groupes socioprofessionnels
Dans le but de présenter exhaustivement les modèles de ségrégation dans le temps, nous avons choisi trois indices complexes en utilisant les données concernant les catégories professionnelles générales : l’indice de dissimilarité (D), qui représente les niveaux de concentration spatiale, l’indice d’exposition normalisé (P) calcule les niveaux d’exposition (isolement), et l’indice de Gini mesure en même temps l’inégalité de distribution spatiale et la concentration spatiale. Indice de dissimilarité (D) Les valeurs de l’indice D vont de 0 à 1 – 0 indiquant l’absence de ségrégation (toutes les unités spatiales sont mixtes et présentent les mêmes pourcentages que l’ensemble de la zone étudiée) et 1 indiquant la ségrégation absolue (mixité nulle dans toutes les unités spatiales). L’indice s’interprète facilement comme le pourcentage du groupe A (p. ex. les migrants) qui devrait changer de domicile pour avoir la même distribution spatiale que le groupe de référence B (p. ex. l’ensemble de la population). Indice de Gini Cet indice est utilisé pour mesurer l’inégalité de revenu au niveau des subdivisions spatiales. Le coefficient de Gini a des valeurs comprises entre 0 (égalité parfaite) et 1 (inégalité maximale). On peut aussi l’utiliser toutefois pour analyser la ségrégation entre groupes de population. Dans le cas d’une ville, la valeur de l’indice décrit l’écart entre la distribution des groupes de population en zones partielles et sa distribution sur l’ensemble de la ville. Indice d’exposition / isolement normalisé (P*) Les indices d’exposition et d’isolement mesurent la probabilité pour un membre d’un groupe d’interagir avec d’autres membres du même groupe ou avec des membres d’autres groupes. L’indice d’isolement a des valeurs entre 0 et 1, qui indiquent respectivement une ségrégation nulle ou complète. Au cas où l’indice d’isolement (xPx) ne concerne qu’un groupe de la population, il détermine la probabilité de contact intragroupe, c’est-à-dire la probabilité moyenne d’interaction (exposition) entre les membres du même groupe, et donc également la probabilité d’isolement par rapport aux membres des autres catégories, dans toutes les unités spatiales de la zone étudiée. |
Conclusion
Pour résumer, l’inégalité de revenu présente au cours des dernières années une relative stabilité à des niveaux plus bas que lors de la période de croissance -depuis la période de stabilité de la croissance jusqu’en 2010− et elle joue un rôle de levier pour réduire la ségrégation liée au revenu, en particulier pour les tranches de revenus intermédiaires (qui convergent désormais vers des niveaux plus bas). L’inégalité spatiale en fonction du revenu, d’un autre côté, fait partie intégrante de la physionomie de l’espace athénien, mais son intensité et sa délimitation révèlent un processus dynamique certainement lié au développement de l’inégalité de revenu. Du point de vue diachronique, on observe une tendance à l’« enfermement » des zones à hauts revenus parallèlement au « départ » et à l’« intégration » des catégories moyennes dans des zones à revenu plus faible. Les tranches de revenus inférieures ne semblent pas devoir faire face à un isolement et ce fait, pour l’instant, est un indice de l’absence relative d’îlots de pauvreté dans l’espace urbain.
Référence de la notice
Pantazis, P., Psycharis, Y. (2016) Ségrégation résidentielle due au revenu imposable dans la zone métropolitaine d’Athènes, in Maloutas Th., Spyrellis S. (éds), Atlas Social d’Athènes. Recueil électronique de textes et de matériel d’accompagnement. URL: https://www.athenssocialatlas.gr/fr/article/segregation-selon-le-revenu/ , DOI: 10.17902/20971.58
Référence de l’Atlas
Maloutas Th., Spyrellis S. (éd.) (2015) Atlas Social d’Athènes. Recueil électronique de textes et de matériel d’accompagnement. URL: https://www.athenssocialatlas.gr/fr , DOI: 10.17902/20971.9
Références
- Καλογήρου Σ (2011) Χωρικές ανισότητες και ερµηνευτικοί παράγοντες της γεωγραφικής κατανομής του δηλωθέντος εισοδήματος στην Ελλάδα. Αειχώρος 15: 68–101. Available from: http://www.aeihoros.gr/article/el/xorikes-anisotites-kai-ermineutikoi-paragontes-tis-geografikis-katanomis-tou-dilothentos-eisodimatos-stin-ellada.
- Μαλούτας Θ (2002) Η κοινωνική μορφολογία των πόλεων. Στο: Μαλούτας Θ (επιμ.), Κοινωνικός και Οικονομικός Άτλας της Ελλάδας. Οι πόλεις, Αθήνα, Βόλος: Εθνικό Κέντρο Κοινωνικών Ερευνών, Gutenberg, Γιώργος & Κώστας Δαρδανός, Πανεπιστημιακές Εκδόσεις Θεσσαλίας.
- Deurloo R and Musterd S (2001) Residential profiles of Surinamese and Moroccans in Amsterdam. Urban Studies, SAGE Publications 38(3): 467–485.
- Reardon SF, Matthews SA, O’Sullivan D, et al. (2008) The geographic scale of metropolitan racial segregation. Demography, Springer 45(3): 489–514.
- Rey SJ (2001) Spatial empirics for economic growth and convergence. Geographical Analysis, Wiley Online Library 33(3): 195–214.

